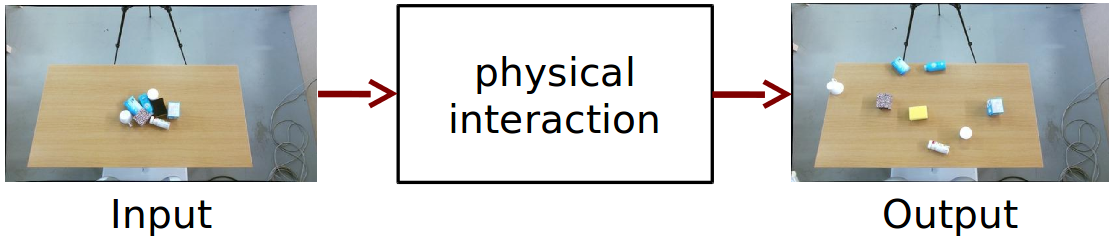
Removing Clutter is Hard
The objective of object singulation is to separate a set of cluttered objects through physical interaction. This poses a substantial challenge for robots, especially when the scenes consist of unknown objects. The capability to operate in such unstructured scenes is regarded as relevant for future service robots. The input into your system is a cluttered scene of unknown objects and the output is a well separated scene that we get after the robot performed a sequence of learned push actions.
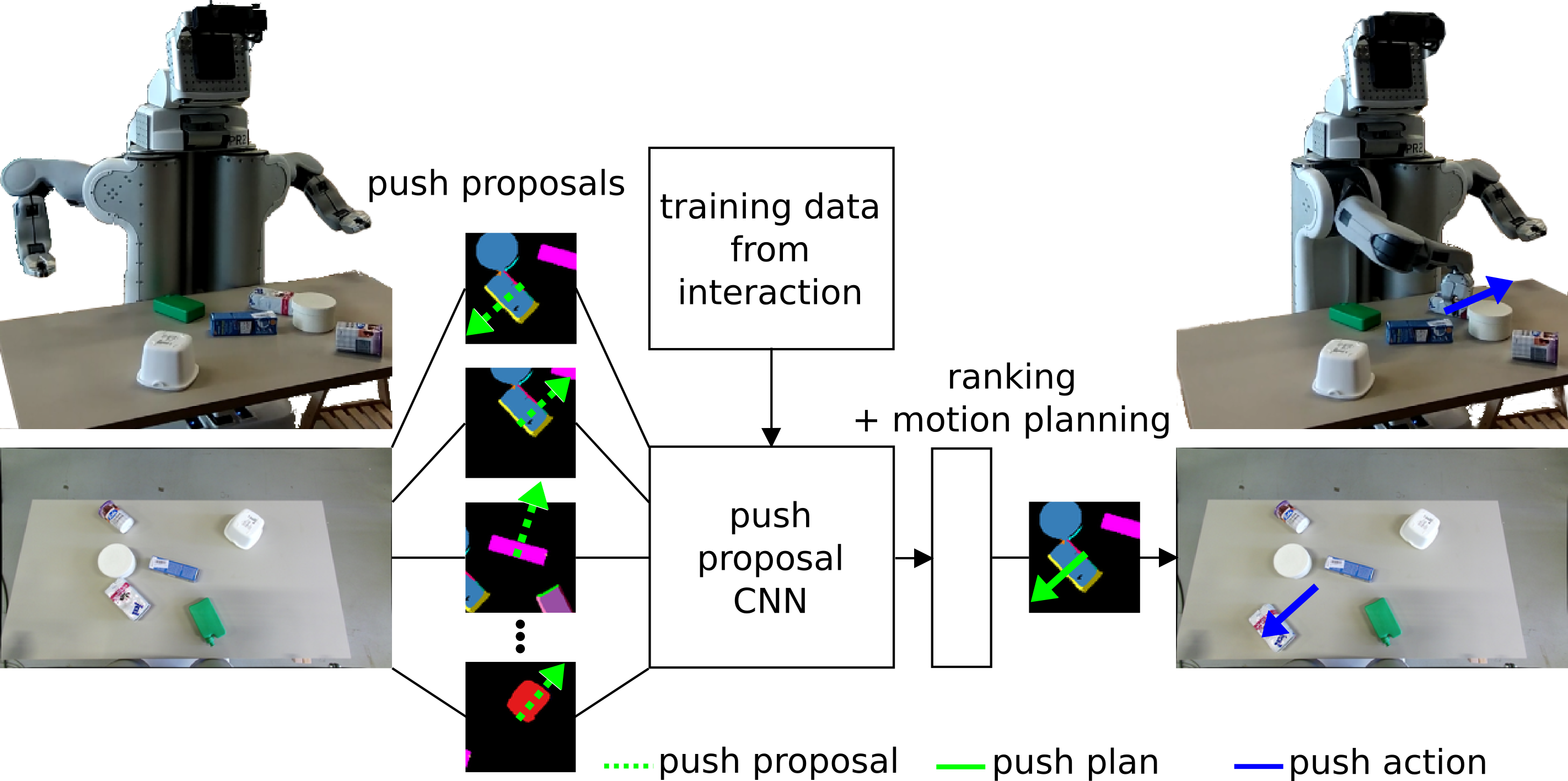
Method
To enable the robot to interact with unknown objets we propose a learning-based perspective. We train a convolutional neural network classifier using experiences that the robot collects from exploratory interaction with a large amount of arbitrary object scenes. The collected interactions are labeled by an expert user as good or bad actions. Actions that led to separation of an object are labeled as good and actions that did not result in separation of an object are labeled as bad. At test time we employ the trained network to predict the singulation success of a candidate action from a set of possible actions. In this work, an action consists of a pre-specified straight-line push. Therefore, we denote the set of possible actions as push proposals and the convolutional neural network respectively as push proposal network. The task of the push proposal network is to classify each proposal from the set of push proposals. The classified proposals are sorted based on the probability of singulation success, starting with the proposal that received the highest probability prediction. Given an arbitray scene consisting of cluttered objects the robot performs a sequence of push actions that leads to a singulation of all objects with higher accuracy then prior work. We achieve a success rate of 70% for singulating 6 unknown objects in clutter and achieve a promising success rate of 40% with 8 unknown objects.